- Audio/transcription alignment problem
- General method: time transformation fitting
- Existing solutions
- Synchronization with STT and sequence alignment
- Implementation
- In part II
Audio/transcription alignment problem
Assume given:
- An audio track (movie, podcast…)
- A transcription of the spoken content of the track, which is unfortunately time-wise misaligned or entirely unaligned with the audio track.
For instance, misalignment can occur when the transcription corresponds to a slightly different audio track, caused by different framerate or extra/missing content at the beginning or throughout. This can lead to delays ranging from less than a second to tens of seconds, all quite noticeable.
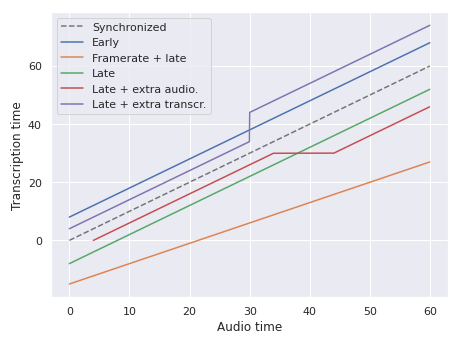
Different examples of misalignments between audio and transcription.
An example that many will have encountered is video subtitles, which will be the main case considered herein. Misalignments usually originate from advertisements or slightly different cuts (extra/missing scenes).
All examples on this page are from the Blender Studio open films,
(CC) Blender Foundation. This is Sprite Fright (2021).
The natural question that will be discussed is:
Can the transcription be automatically (re-)aligned to the audio track?
General method: time transformation fitting
Formally, the alignment problem is about finding a transformation $T$ from the time frame of the transcription to that of the audio.
A general method for solving this is to:
- Obtain samples from that transformation, namely pairs of timestamps (transcription, audio).
- Reconstruct the transformation using the samples as well as priors on what shape the transformation can take (e.g. piecewise linear). This must be robust to noisy or erroneous samples.
- Apply the transformation to the transcription to resynchronize it.
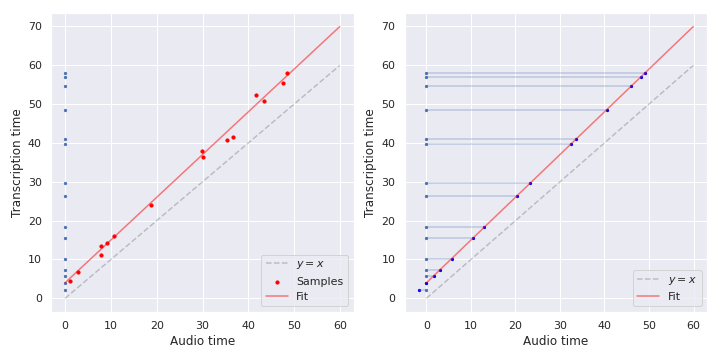
Fitting a linear time transformation using samples (left),
before using it to retime the transcription (right).
Identifying pairs of timestamps
The first step, obtaining sample pairs from the transformation, must of course use information present in the transcription. In the case of subtitles, this is sentences with their start and end time. In SubRip notation:
23
00:01:40,708 --> 00:01:44,667
Oy, fungus freak! Make yourself useful and fix the tent.
24
00:01:44,667 --> 00:01:48,917
Oh, a bit of friendly campsite ribbing. Fun.
Waveform and spectrogram (computed with Audacity),
corresponding to the dialogue segment above from Sprite Fright.
From there, the following strategies naturally arise:
Perform automatic Speech-to-Text (STT) on the audio tracks, effectively generating a second imperfect transcription, whose textual content can be paired with the first one, yielding timestamp pairs.
Transcription STT 00:03:30,667 --> 00:03:34,417 00:04:00,000 --> 00:04:05,000 We sprite balance to the forest. <-> we bright balance the forest => 00:03:30,667 <-> 00:04,000This needs to take into account that the second transcription may frequently be incomplete or incorrect. After all, if it were perfect, it could be used directly. Due to that and to ambiguities (e.g. repeated sentences at different times), the pairing is not trivial to carry out.
An alternative is to discard the contents of the transcription, and only use the information that there is voice during a certain time span. More precisely, STT is replaced by Voice Activity Detection (VAD), and the pairing requires aligning two sets of intervals.
VAD ______X______XXXX____XXXXXX____________XXX___ Transcription _________XXXX_____XXXXXXX________XXXX________In the example above, the VAD has a false positive at the beginning and the segments from the transcriptions are not perfectly matched. However, one can still clearly identify a left shift of the transcription with respect to the audio track.
The advantage compared to STT is that VAD is a far simpler problem, allowing faster runtime, higher precision (in the respective tasks), and language-agnosticity. On the other hand, the loss of information can make the matching more challenging.
Waveform and spectrogram from the beginning of Agent 327,
with the only voice segment (“This is 327, I’m going in”) marked.
Existing solutions
The most important distinguishing factors of existing tools for subtitle synchronization are:
- Processing speed.
- Quality of the resulting alignment.
- Type of misalignment that can be corrected: simple linear shifts (L) or more complex transformations (C).
- Requirements on the audio: language, tolerable amount of noise…
A semi-exhaustive list of projects (as of 2023), ordered by repository creation date, is given in the following table:
| Name | Method | Shifts | Language | Commits/ | Date |
|---|---|---|---|---|---|
| kaegi/almtass | VAD | C | Rust | 50/828 | 2017-02 |
| AlmtbertoSabater [*] | VAD | L | Py | 7/66 | 2017-09 |
| tympanix/subsync [*] | VAD | L | Py | 70/125 | 2018-03 |
| subsync.online, sc0ty/subsync | Transcription | L | C++/Py | 316/1003 | 2018-10 |
| oseiskar/autosubsync [*] | VAD | Fixed | Py | 70/305 | 2018-09 |
| pums974/srtsync | VAD, FFT almt | L | Py | 19/50 | 2018-12 |
| smacke/ffsubsync | VAD, FFT almt | L | Py | 363/6100 | 2019-02 |
| captionpalmt, Overdrivr/autosync [*] | VAD | L | Py | 98/10 | 2019-04 |
| baxtree/subalmtigner | Local+global RNN | C | Py | 266/336 | 2019-12 |
| Amazon Prime Video | VAD, drift model | C | ? | - | 2023-03 |
[*]: based on Sabater’s write-up on a CNN for VAD combined with a linear alignment search.
There is also a certain number of scientific articles on the subject (albeit rarely containing source code), such as:
- I. González-Carrasco, L. Puente, B. Ruiz-Mezcua and J. L. López-Cuadrado, Sub-Sync: Automatic Synchronization of Subtitles in the Broadcasting of True Live programs in Spanish in IEEE Access, vol. 7, 2019. Link.
- See also the 2023 follow-up paper, Masiello-Ruiz, J.M., Ruiz-Mezcua, B., Martinez, P. et al. Synchro-Sub, an adaptive multi-algorithm framework for real-time subtitling synchronisation of multi-type TV programmes. Computing 105, 1467–1495 (2023)
VAD methods
Methods using Voice Activity Detection (VAD, see above) are the most common ones.
The voice activity detection is carried out with either:
- Google’s WebRTC VAD module, a Gaussian Mixture Model, which is very fast but sensitive to noise.
- A custom CNN operating on Mel spectrograms, for the methods based on [*].
- A custom Bi-GRU model for Amazon Prime’s proprietary implementation, aimed at robustness to noise and language changes.
auditok, simply based on signal amplitude.
Alignment is usually performed by minimizing cross-entropy between the VAD probabilities and the transcription indicator, either:
- By testing all possible shifts or a subset thereof (e.g.
autosubsynconly considers shifts occurring from framerate changes). If the VAD and transcription sequences both have length $n$, the exhaustive search across offsets has complexity $O(n^2)$. - By computing a Fast Fourier Transform and finding its extremum, which achieves a complexity of $O(n\log{n})$ to find the best offset.
- By more complex algorithms, e.g. the subject of kaegis’s Bachelor thesis. In particular, the latter considers more general shifts than linear ones. Amazon Prime are using another machine learning model to detect drift.
Transcription methods
Transcription (see above) is the technique used by sc0ty/subsync, employing Sphinx for STT.
The synchronization algorithm fits a line on the timings of the transcription/subtitle words, based on time and word similarity.
Obvious drawbacks compared to other methods are speed and not being language-agnostic.
Other methods
The approach used by subaligner. is more “end-to-end”, as a neural network directly predicts offsets. To handle more complex transformation than simple offsets, this is applied in two stages, first globally and then locally. Note that this does not quite fit into the general method described above.
Synchronization with STT and sequence alignment
Goals
After evaluating some of the implementations above, I wanted to try implementing an alternative method with the following goals:
- Fast processing speed (ideally much faster than real time) and low resource usage.
The implementations above that provide the best quality are sometimes quite slow and/or resource intensive. - Ability to handle complex transformations between the audio and subtitles time references.
Note that many of the projects above only handle globally linear transformations. - Accurate synchronizations.
- Relatively simple and modular implementation.
- Single-binary deployment.
- Rust implementation, to meet the above goals.
Method
The idea follows the general method outlined above with:
- Speech-to-text to extract as much information as possible for the synchronization.
- This will require special care to meet the first goal of fast processing speed.
- An unavoidable drawback is that the implementation will not be language-agnostic.
- The Needleman-Wunsch algorithm to perform alignment of the two transcriptions, at the word level.
This is a simple yet powerful dynamic programming algorithm. The complexity of a basic implementation is equal to the product of the lengths of the sequences, which should still run very fast. The sequences considered here are much shorter than the sequences of segments in VAD.
This is also the technique used in González-Carrasco et al. (2019). - Transformation fitting according to some fairly generic assumptions, e.g. splines or piecewise linear.
Altogether, there are five steps:
- Subtitle parsing and word-level decomposition
- Speech-to-text
- Word alignment between the STT output and the decomposed subtitle
- Fitting
- Resynchronization

Architecture of the alignment pipeline.
These are described in the next sections.
Implementation
Step 1: Subtitle parsing and decomposition
Restricting to the common SubRip format illustrated above, a simple parser can be written using the chumsky parser combinator crate. A .srt file is parsed as:
pub struct Subtitle {
entries: Vec<SubtitleEntry>,
}
pub struct SubtitleEntry {
pub sequence: u64,
pub start: Timestamp,
pub end: Timestamp,
pub text: String,
}
The earlier description of the extraction of pairs of timestamps using STT remained vague on how the STT transcription is paired with the original subtitles. This is done at the word level: right after parsing, the subtitle is decomposed into a Vec<Word>:
pub struct Word {
pub start: Timestamp,
pub end: Timestamp,
pub text: String,
pub confidence: f32,
}
To do so, it is assumed that the number of characters per second is constant in each SubtitleEntry, which is a good enough approximation. The confidence field will be used later with the transcriptions; here it is simply set to 1.0.
For example, the entry
4
00:00:28,375 --> 00:00:30,833
Can’t believe we got stuck with the tree hugger.
gets decomposed as
00:00:28,375 --> 00:00:28,719 [1.00]: Can’t
00:00:28,719 --> 00:00:29,063 [1.00]: believe
00:00:29,063 --> 00:00:29,161 [1.00]: we
00:00:29,161 --> 00:00:29,308 [1.00]: got
00:00:29,308 --> 00:00:29,554 [1.00]: stuck
00:00:29,554 --> 00:00:29,751 [1.00]: with
00:00:29,751 --> 00:00:29,898 [1.00]: the
00:00:29,898 --> 00:00:30,095 [1.00]: tree
00:00:30,095 --> 00:00:30,439 [1.00]: hugger.
It would also have been possible to use sentences as the input to the alignment, which would have avoided this decomposition. However, STT does not necessarily generate full sentences, so the analogous step to decomposition here would have been to assemble sentences. Later, instead of scoring pairs of words, pairs of sentences would have been scored.
Step 2: Speech-to-text
Speech-to-text is the most computationally expensive step of the process, and care has to be taken to meet the first goal of a faster-than-real-time overall processing.
To this goal, the Silero STT models are used. They are accurate, very fast even on the CPU, and easy to integrate thanks to an ONNX export. They are available in English, German, Spanish and Ukrainian. Details about the models are provided in this article; the starting point is Facebook’s wav2letter.
The model takes as input samples at 16k Hz, and produce probabilities over a set of 999 tokens. More precisely, chunks of 2 seconds are fed to the model, and 13 distributions over tokens per seconds are retrieved.
Audio decoding and resampling is done using the gstreamer Rust bindings.
Inference is implemented the Rust onnxruntime bindings and takes ~50-100 ms for each chunk on a laptop CPU (AMD Ryzen 7 3700U), namely ~20-40x real-time speed. Despite the inputs and outputs having fixed size, there is quite some variance, in particular in the first few batches (possibly from onnxrutime optimizations).
A simple greedy decoding is performed, where the most probable token is selected for each output sample. Then, words are reassembled from tokens, by considering blanks and repetitions.
_ 1.00 00:00:32,000
for 0.99 00:00:32,077
0.95 00:00:32,154
0.98 00:00:32,231
one 1.00 00:00:32,308
0.77 00:00:32,385
1.00 00:00:32,462
more 1.00 00:00:32,539
0.89 00:00:32,616
1.00 00:00:32,693
an 1.00 00:00:32,770
an 1.00 00:00:32,847
im 1.00 00:00:32,924
al 0.93 00:00:33,001
al 0.76 00:00:33,078
0.78 00:00:33,155
0.70 00:00:33,232
0.93 00:00:33,309
0.60 00:00:33,386
s 0.79 00:00:33,463
we 0.92 00:00:33,540
ar 0.96 00:00:33,617
_ 0.50 00:00:33,694
_ 0.51 00:00:33,771
_ 0.89 00:00:33,848
_ 0.98 00:00:33,925
for / one / more / animal / swear
This could be improved in many ways, for example by using beam search, scoring with the word probabilities and/or a language model. It would also be possible to check and correct words that do not exist (e.g. nat,j,ure is decoded to natjure), but robustness to misspellings will be taken into account in the score used for alignment.
Step 3: Word alignment
The previous steps, STT and subtitle parsing/decomposition, yield two sets of Words, namely text with timestamp and confidence.
In this step, the Needleman-Wunsch algorithm is applied to find a global alignment between these two sets. Gaps can be inserted, displayed below as _.
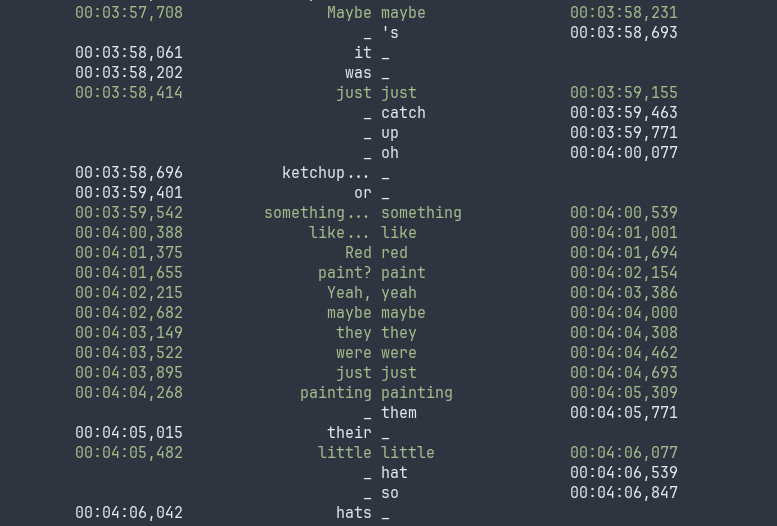
Extract from an alignment, with a high density of matches.
The subtitles are on the left, the transcription on the right.
Note the transcription errors: missing “it was”, “catch up” vs “ketchup”,
“oh” is “or”, “them” vs “their”, and “hat so” vs “hats”.
Every pair of word is compared and assigned a score. Every word is first normalized with respect to punctuation and capitalization. The score is then simply the product of the confidence if the normalized words match, 0 otherwise.
More complex normalization could of course be considered, as well as less strict metrics, such as the Levenshtein edit distance.
Gaps are assigned a constant score, which should reflect the fact that gaps are more acceptable than incorrect matches, which would pollute the transformation fitting.
The Needleman-Wunsch dynamic programming algorithm then finds the alignment that maximizes the score.
pub struct Alignment<'a, T> {
pub score: f32,
pub choices: Vec<(Option<&'a T>, Option<&'a T>)>,
}
impl Alignment {
pub fn compute(
left: &'a [T],
right: &'a [T],
gap_penalty: f32,
score_fn: impl Fn(&T, &T) -> f32,
) -> Result<Self, errors::Error> {
// ..
}
}
This runs quite fast:
Computing scores with 486 vs 849 words
Done computing scores, 2393 nonzero values
Done computing alignment in 63 ms
The second line shows that less than 1% of the words have a nonzero score. A simple sparse matrix structure is used to hold these.
Interlude: Testing Steps 1-3
The pipeline so far can be tested by plotting the two sets of words with the alignments.
In the following plots, for the Blender Studios films, the STT words are up (in orange) and the subtitle words are down (in blue). The horizontal axis is time.
Given that the subtitles were synchronized, non-vertical lines denote errors in the alignment. As the alignment does not depend on the timestamp, the observations would still apply if the subtitles were not synchronized.
| Name | Word ratio | Aligned | Bad matches | Distance [s] |
|---|---|---|---|---|
| Agent 327 | 199% | 55% | 0 | -0.26 ± 0.34 |
| Cosmos Laundromat | 113% | 57% | 0 | -0.33 ± 0.49 |
| Elephants Dream | 145% | 37% | 0 | -2.51 ± 10.3 |
| Sprite Fright | 175% | 40% | 0 | 0.65 ± 5.82 |
The alignment percentage is computed with respect to the words from the subtitles.
The “word ratio” is the ratio of words in the transcriptions over words in the subtitles.
The “Distance” column indicates the mean and standard deviation of the time difference between matches. For already aligned subtitles, this should be close to zero.
| Agent 327 | 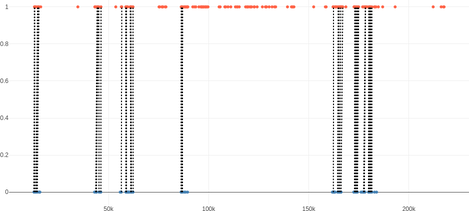 |
| Cosmos Laundromat | 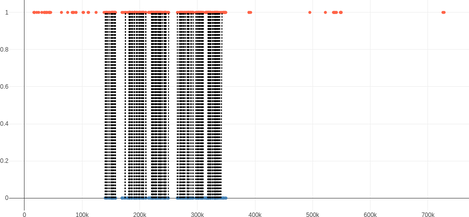 |
| Elephant Dream | 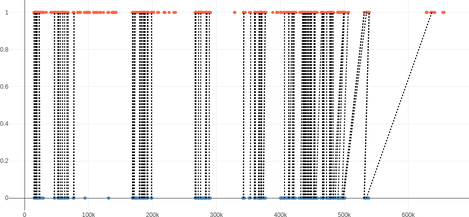 |
| Sprite Fright |
This is great overall: there is a large number of matches, in each of the sections with spoken content, and most are correct.
- For a good fit able to handle complex transformation, enough (correct) matches are required in each section with spoken content.
- The transcription usually have many false positives (mostly during noisy action sequences), which is fine as long as they do not get matched. This appears in the table as the “Transcription/srt” word ratio, which should be ideally close to 100%.
- Upon close inspection, it appears that the incorrect matches arise from short and common words (“yes”, “no”, “and”), in sections with sparser subtitles or transcriptions.
These could be ignored or penalized, but this will rather be done as part of the fitting.
Keeping only the matched pairs, a set of (Word, Word) pairs is obtained, corresponding respectively to a subtitle and transcription word.
Step 4: Fitting
As explained earlier, this step is responsible for estimating the time transformation $T$ between the subtitles time frame to that of the transcription, using the pairs of timestamps $(t_1, t_2)$ arising from the pairs of matched words $(w_1,w_2)$ from the previous step.
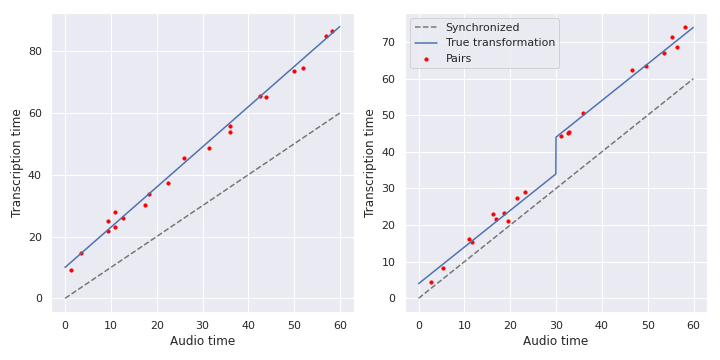
A linear and a piecewise-linear transformation (extra transcription content).
Many of the existing methods (see above) assume that the transformation is a simple offset $T(x)=x+b$ or a linear transformation $T(x)=ax+b$ (to handle e.g. framerate changes). In this case, a simple least squares fit is already quite efficient (see the left plot above).
To handle the case where there is extra content in either the transcription or the audio (e.g. right plot above), piecewise linear transformations are considered.
It is important to note that “segmented regression” libraries such as pwlf (Python), piecewise-regression (Python) or plr (Rust) are solving a different problem, where the functions are assumed to be continuous. They perform either a grid search over breakpoints, or a joint optimization between breakpoints and coefficients. In the case at hand, the functions are by definition discontinuous, rather corresponding to the stegmented model handled (for a single breakpoint) by chngpt.
The strategy used for the fit is to:
- Cluster the pairs of timestamps in 2 dimensions.
- Discard clusters with too few points.
- Perform a linear fit in each cluster.
- Given a new point, assign it to the nearest cluster in 1 dimension and use the linear fit.
The number of clusters is selected with a loss optimizing for a low loss and a low number of clusters (complexity/generalization trade-off).
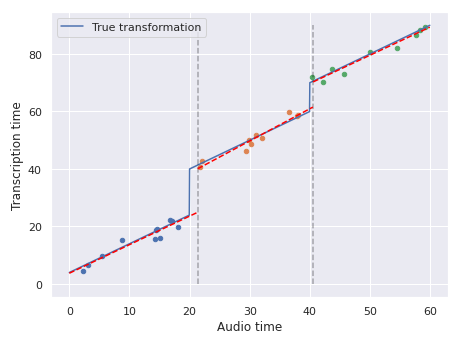
Fitting a piecewise-linear time transformation.
The blue line is the true function and the red lines are the fits.
The following plots display the same data as earlier — the result of the alignment — but with the setup of the above plot (i.e. transcription on the vertical axis). The dotted diagonal line is $y=x$, on which all matches should lie given that the subtitles are aligned.
| Agent 327 | 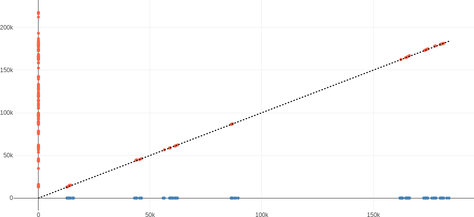 |
| Cosmos Laundromat | 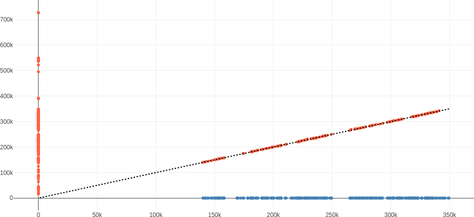 |
| Elephant Dream | 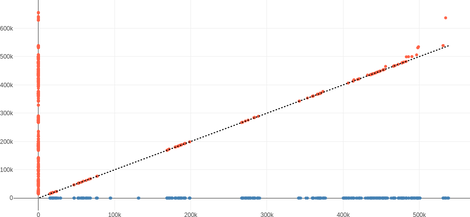 |
| Sprite Fright |
The outliers would not be an issue when fitting a global linear transformation, but it is important to remove them to be able to handle more complex functions $T$.
Step 5: Resynchronization
Once the time transformation $T$ has been estimated, resynchronization consists simply in applying $T$ to the original subtitles.
In part II
The second part of this note will (when time permits):
- Analyze the quality of the pipeline by applying synthetic transformations to aligned subtitles, and checking that the original alignment can be recovered.
- Compare the alignment quality and speed of the existing methods surveyed above.
- Compare recent speech-to-text models against Silero STT.
- Provide the source code, as well as binaries.