paperless-ngx is a great self-hosted open source tool to manage administrative documents (letters, bills, forms, etc) painlessly.
After upload (through browser, mobile app or email), paperless-ngx performs Optical Character Recognition on the documents, and metadata can be added manually or automatically. At the end of this process, a fully searchable document archive is available, a significant improvement over sifting through a piles of paper.
Document metadata
The primary metadata for a document are:
- The correspondent and document category, which can often be correctly assigned via manual or learnt rules.
- The category (e.g. invoice, letter, card), which can also similarly easily be assigned automatically.
- The date, which
paperless-ngxdoes a good job at guessing from the document text, throughdateparser. - The title, which is by default the filename of the uploaded document.
- For financial documents (e.g. invoices, bank extracts), it is also convenient to have the total amount as a custom field.
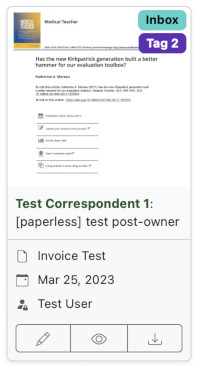
A document with metadata: correspondent, title, category, date, tags, archive id.
LLM-based metadata extraction
Unlike correspondent, category and date, there is no simple built-in way to automatically assign the title and monetary amount metadata.
In a workflow where documents are either imported from the producer (bank statements, PDF attached to emails) or scanned manually, the default title (the filename) is usually a pretty poor description of the contents.
This, and more generally extracting general information from documents, is a task well-suited for large language models, as discussed in this paperless-ngx GitHub issue, and several tools have been developed to this effect:
| Tool | Fields | Language | Remarks |
|---|---|---|---|
paperless-gpt | title, tags and corresp. | Go | LLM-based OCR, web UI for change review |
doclytics | title, corresp., date, category and others | Rust | |
paperless-ai | title, corresp., tags, category | Javascript | Web UI for change review |
The mode of operation of each is:
Retrieve document to process from
paperless-ngxvia the REST API.Send the document to an LLM API server, with an adequate prompt to retrieve the desired fields.
The data sent is either:- the raw document itself (PDF, images) or
- the content already OCR’ed by
paperless-ngxvia OCRmyPDF (wrapping tesseract).
The first option has the advantage of a potential higher accuracy, especially with complex documents.
Parse the output, usually constrained to be JSON.
Update the
paperless-ngxmetadata via the API, possibly after user validation.
Thanks to the ubiquity of OpenAI API compatibility, these tools are usually compatible with a wide range of commercial or locally-hosted models (e.g. via ollama).
Requirements
The solution I was seeking had the following requirements:
- Use of a local language model (say running on a RTX 3060 with 12 GB of VRAM), as confidential documents are being processed, even though commercial offerings would without doubt be much faster and more accurate.
- Auditable code with reasonable dependencies, for the same reasons.
- Accurate processing, with little to no manual review or corrections needed.
- Good (time) performance, in particular when processing numerous existing documents.
- Support of multilingual documents (English, French, German), but consistently producing titles in English.
- Support of long documents (despite models having a limited context size, especially when running them on limited memory).
Out-of scope are:
- Other fields than title and amount.
- External OCR, as the one performed by
paperless-ngxviatesseractis already excellent in most cases.
Evaluating open models
From the requirements above, the model should be:
- Below ~24B parameters (assuming we can use up to a 4-bit quantization), to fit mostly in GPU memory. On the other hand, to be adequate, the model likely needs to be at least ~8B parameters.
- Strong in multilingual tasks (at least English, French and German).
At the time of writing (March 2025), good candidates are:
| Company | Model | Parameters | Context [t] | Multilingual | Speed [t/s] | CPU offloading |
|---|---|---|---|---|---|---|
| Microsoft | phi-4 | 14B | 16k | No 1 | 990 / 24 | 5% (Q5) |
| Alibaba | Qwen 2.5 | 14B | 128k | Yes 2 | 970 / 21 | 5% (Q5) |
| Meta | llama 3.1 | 8B | 128k | Yes 3 | 2000 / 35 | - (Q8) |
| Mistral | NeMo | 12B | 128k | Yes 4 | 1300 / 32 | - (Q5) |
| Mistral | Small 3 | 24B | 32k | Yes 5 | 500 / 9 | 30% (Q4) |
| Gemma 3 | 12B | 128k | Yes 6 | 1230 / 31 7 | - (Q5) |
The speeds are given in tokens per second, separately for prompt decoding and generation.
The quantizations are Q*_K_M K-quants (see later for a discussion of I-quants).
The speed and CPU offloading (for a 5k tokens context size with Q4_0 quantization) are computed on a RTX 3060 with 12 GB VRAM, with an AMD Ryzen 9 7900, using ollama for inference.
From the Microsoft phi-4 model summary:
Multilingual data constitutes about 8% of our overall data. […] The model is trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English. phi-4 is not intended to support multilingual use.
From the announcements of Qwen2 (June 2024) and Qwen2.5:
Significant efforts were directed towards augmenting both the volume and quality of pretraining and instruction-tuning datasets across a diverse linguistic spectrum, beyond English and Chinese, to bolster its multilingual competencies. Although large language models possess an inherent capacity to generalize to other languages, we explicitly highlight the inclusion of 27 additional languages in our training. They also maintain multilingual support for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more. Below, we provide basic information about the models and details of the supported languages.
See also the announcement of the original Qwen model (January 2024):
Models are sufficiently trained with 2-3 trillion tokens. The pretraining data are multilingual, and thus Qwen is essentially a multilingual model instead of a model of a single language or bilingual. Note that due to the limitations of our pretraining data, the model is strongly capable of English and Chinese and also capable of other languages, such as Spanish, French, and Japanese.
From the llama 3.1 model card:
Supported languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
From the Mistral NeMo announcement
The model is designed for global, multilingual applications. It is trained on function calling, has a large context window, and is particularly strong in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi
From the Mistral Small 3 model card:
Supports dozens of languages, including English, French, German, Spanish, Italian, Chinese, Japanese, Korean, Portuguese, Dutch, and Polish.
From the model card and the technical report:
Multilingual support in over 140 languages
We also increase the amount of multilingual data to improve language coverage. We add both monolingual and parallel data, and we handle the imbalance in language representation […]
Disabling KV cache quantization and running under llama.cpp rather than ollama, see below.
Speed
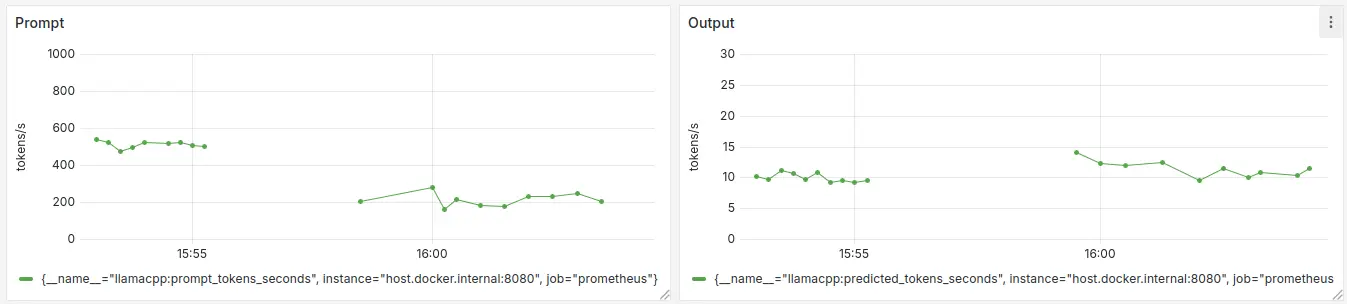
Comparing processing speeds (prompt and generation) of two models in Grafana, using Prometheus to scrape the metrics exposed by llama.cpp.
A typical document will be around 1000 tokens, with an output of length ~10 tokens. This gives the following approximate processing speeds:
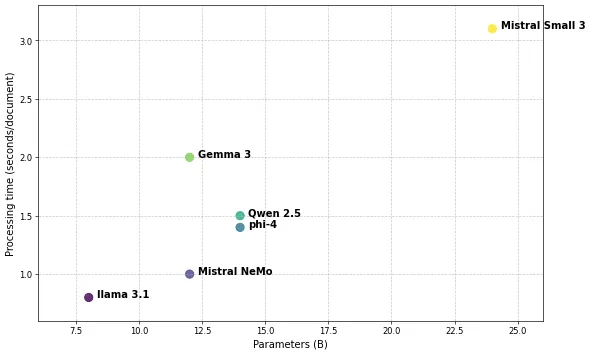
Number of parameters vs processing time.
The throughput can be increased through parallel processing; see below. However, this is already reasonable enough to process a moderately-sized existing collection, as well as new documents.
Accuracy evaluation
The following system prompt was used after some trial-and-error:
Provide a title and amount (CHF, if relevant) for the text.
Respect the following rules for the title:
- Concise (no unnecessary words)
- No markup.
- In English, even if the text is in another language
- No names of persons or companies
- Max 5 words
Output in JSON, with keys "title" and "amount".
Text:
The “even if the text is in another language” instruction avoids cases where the models ignore the “in English” request when the text is in another language. For now, we use JSON output, but see below.
The “No name” instruction prevents the title from containing superfluous information when combined with the correspondent.
A rough manual evaluation shows the following, on the titles output alone:
| Model | Size | Assessment | |
|---|---|---|---|
| Meta llama 3.1 | 8B | Poor titles, not always in English. | |
| Mistral NeMo | 12B | Outputs markup (**Title**: ....), and titles not always in English for documents in other languages. | |
| Alibaba Qwen 2.5 | 14B | Creates relatively good titles, although sometimes subtly wrong (e.g. No-show fee instead of Doctor appointment) and sometimes including the monetary amount in the title. | |
| Mistral Small 3 | 24B | Generally excellent at providing accurate title, in English. | |
| Gemma 3 | 12B | Despite being half the size of Mistral Small 3, seems to produce equally good output (if not slightly worse) for this task. |
Unsurprisingly, the other models that do not claim to be multilingual (e.g. phi-4) have relatively poor performance on the non-English documents.
Optimizing inference
Given we are performing inference with limited resources, it is worth addressing simple optimizations to speed-up processing.
Gemma 3 inference speed
Running Google’s Gemma 3 under ollama with the same parameters as other models yields a prompt processing speed of only 180 tokens/s, an order of magnitude lower than other models of this size.
From this llama.cpp issue (see also this ollama issue), this happens when combining flash attention and KV cache quantization, due to the larger head size. Disabling the KV cache quantization (at the cost of increase memory usage) gives a processing speed of 1000 tokens/s; this is the value reported in the table above.
In practice, the maximum context size that then fits with the Q5-quantized model on 12 GB VRAM is 6144 (or 9216 using a Q4 model quantization) tokens:
init: kv_size = 6144, offload = 1, type_k = 'f16', type_v = 'f16', n_layer = 48, can_shift = 1
llama_context: KV self size = 2304.00 MiB, K (f16): 1152.00 MiB, V (f16): 1152.00 MiB
Simplified structured output grammar
Using JSON structured output to retrieve the title and amount from the model is natural, and supported by ollama (and more generally the OpenAI API).
This works by transforming the JSON schema to a GBNF grammar, which is then used to constrain the sampling, combined with adequate prompting of the model.
However, from the tables above, while prompt processing is relatively fast, generation speed is slow, and producing
{
"title": "",
"amount": ""
}
already requires around 16 tokens.
It is therefore beneficial to use a more compact grammar, e.g.
root ::= string linebreak monetaryAmount
string ::= char+
char ::= [^\n\r]
linebreak ::= "\n" | "\r\n" | "\r"
monetaryAmount ::= amount | "-"
amount ::= digits "." decimalPart
digits ::= [0-9]+
decimalPart ::= [0-9]{2}
while adapting the prompt with:
Output the title on line 1, the amount (float or - if there is none) on line 2.
(when the sampling is not constrained by the grammar, the output matches the format requested in the prompt most of the time, but not always.)
This way, the model is not required to output useless tokens.
Ollama does not (yet) support passing arbitrary GBNF grammars, so this requires using llama.cpp directly (e.g. through llama-server). Note that ollama GGUF models can in many cases 8 be used directly in llama.cpp:
$ # From the ollama data/models folder
$ llama-server -m blobs/sha256-(cat manifests/registry.ollama.ai/library/qwen2.5/14b-instruct-q5_K_M | jq -r '.layers[] | select(.mediaType == "application/vnd.ollama.image.model") | .digest' | cut -d: -f2) ...
Although not Gemma 3; get the GGUF directly here.
Parallel generation
The consistent large difference in speed between prompt processing and generation stems from the fact that the former is parallelized, while the latter cannot due to the autoregressive nature of generation.
Performing parallel queries, which can be batched, allows significantly speeding up the generation phase.
This is supported by llama-server: queries are queued, assigned to “slots”, which are then batched together. The total context size in the flag --ctx-size (dictated by the available memory) is divided evenly among slots, whose number is given by the --parallel flag.
The following table is produced with the llama-batched-bench example from llama.cpp, and gives timings for a prompt of size 1000 and a generation of 10 tokens (matching our use case), with batch size from 1 to 4, on Mistral Small 3:
| Batch size | Prompt processing [t/s] | Generation [t/s] | Total time [s] |
|---|---|---|---|
| 1 | 585.44 | 9.87 | 2.722 |
| 2 | 569.59 | 18.67 | 4.582 |
| 3 | 594.28 | 24.99 | 6.248 |
| 4 | 586.26 | 29.10 | 8.198 |
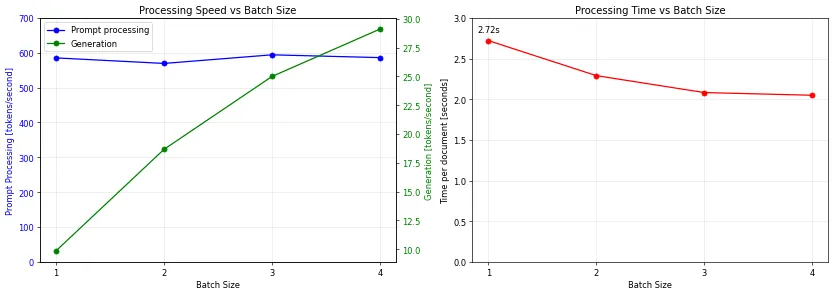
A ~30% speed gain in terms of documents per second can be observed when documents can be processed in parallel (with an underlying 3x speed gain in generation speed). This is easy to do client-side.
This is useful for Mistral Small 3 (up to 4 batches of 5k tokens can fit in memory), but not for Gemma 3 until the KV cache quantization issue is fixed, as only one batch fits in memory.
Context length
It is important to manage the available context length properly, especially when dealing with potentially large documents and limited VRAM. In the worst case scenario:
- The prompt is followed by a very long document.
- The inference engine is configured to roll-over the context when it is exceeded, so that the prompt is ignored.
- The model will spend a long time generating irrelevant output.
Shifting the context and allowing infinite output is the default in llama.cpp, triggering this problem.
On the opposite end, a frequent issue when using ollama is that inputs are silently truncated to the default context size of 2048 tokens.
- The first safety is to disable this behaviour with the
--no-context-shiftand--n-predict 100flags. An error will then be produced if the context is exceeded by the combination of the prompt and the output. - On the client side, we can then truncate the document based on the available context length, expected output size, and prompt length. This can be done combining a heuristic mapping string length to token length with calls to the generation API until it accepts the requests (or using the tokenization endpoint first). This will likely have minimal effect on title assignment accuracy, but might be more annoying for monetary amount determination.
See also this issue on doclytics or this one on paperless-ai.
llama.cpp compilation options
The Arch User Repository provides a llama.cpp-cuda package.
I was initially surprised to see that the prompt evaluation time was 5x slower than in ollama (although with a 2x faster generation speed), see this issue.
Comparing compilations options between ollama and the AUR package, it turns out that the -DGGML_BLAS=ON build option activated in the latter moves more computations than expected to the CPU.
Disabling it gives the expected performance. It would however be nice to get the faster generation speed.
Quantizations
Using more aggressive quantization, so that less slow CPU offloading is necessary, could also be a good option. For example, with Mistral Small 3 and a context size of 5120 tokens:
| Quantization | Speed prompt/gen [t/s] | CPU offloading |
|---|---|---|
Q4_K_M (baseline) | 500 / 9 | 30% |
IQ3_M | 670 / 20 | 5% |
From a cursory check, there seems to be no quality loss on the task.
Plugging the APIs together
Implementing the general mode of operation described above is then relatively trivial.
Minor details in addition to the above:
paperless-ngx- See this discussion to avoid
sqlite3concurrency issues whenPATCH’ing documents. - Monetary custom fields must respect the format
[A-Z]+\d+\.\d{2}, otherwise the server will throw an error. - The custom fields and tags are represented by their IDs rather than their names in the documents. These need to be fetched with separate queries in advance.
- See this discussion to avoid
llama.cpp- The
llama-serverAPI uses requests and response fields not present in the OpenAI API (e.g.grammar,timings); additional endpoints such as/propsand/tokenizeare also useful. - As of the date of writing, this PR is required to avoid a segfault when using parallel processing; see this issue.
- The
See the Rust implementation here.
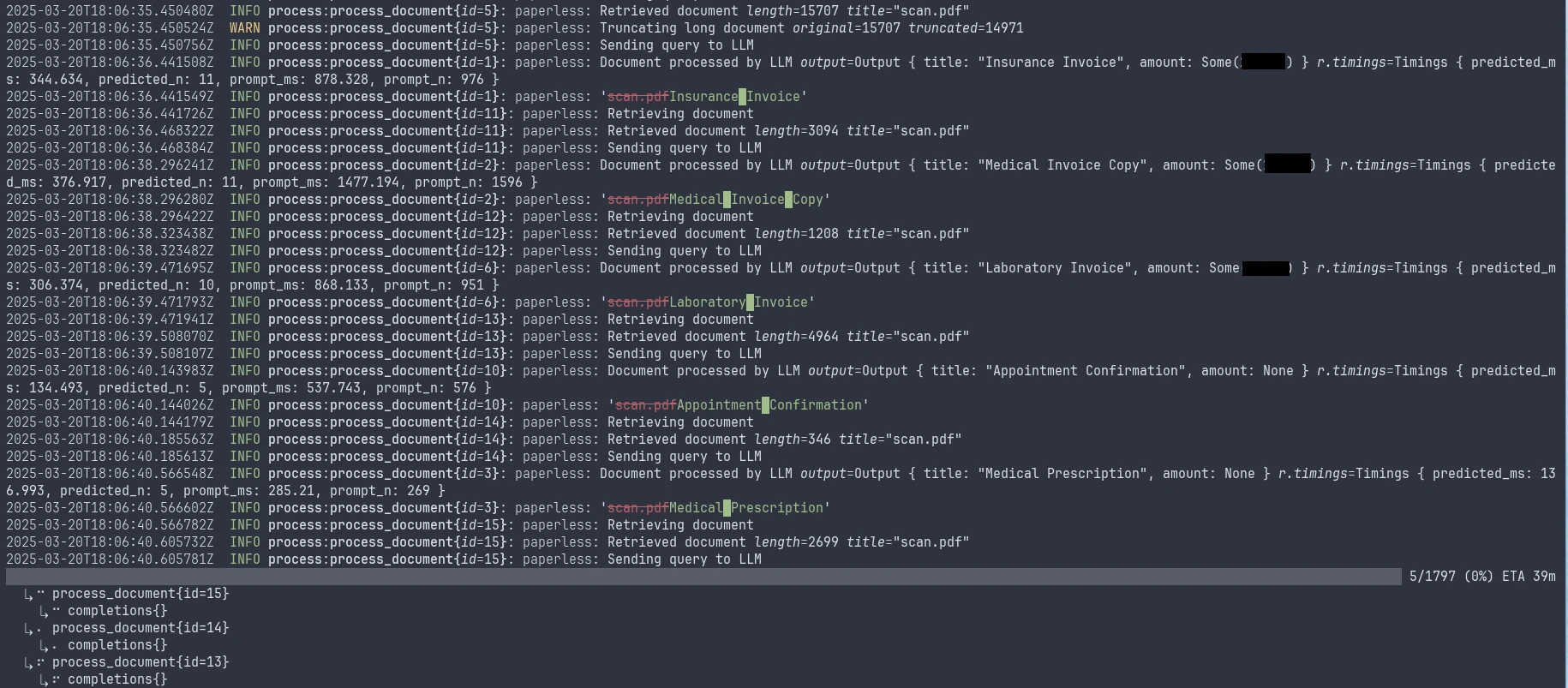
Screenshot of the CLI tool reassigning titles from the scanner’s scan.pdf.