Source code/binaries Github
Contents
LanguageTool
LanguageTool is an open-source alternative to Grammarly for natural language linting (spelling, grammar, style), with a large set of rules. Multiple clients exist for its API, bringing functionalities to Firefox, Chrome, LibreOffice, Thunderbird, emacs, and many more.
Self-hosting LanguageTool
While most users access LanguageTool through the official hosted server (with a free or paid plan), the Java API server can be hosted locally, which can be particularly desirable for privacy reasons (e.g. when editing confidential documents).
Even though the browser extensions are unfortunately closed-source, they still allow custom servers to be specified.
Lightweight LanguageTool API server
Benjamin Minixhofer wrote a Rust crate, nlprule, that is able to parse and then apply LanguageTool rules noticeably faster than the original Java implementation (see this benchmark). More complex rules written in Java are not supported and spellchecking is not implemented, but nevertheless roughly 85% of the LanguageTool grammar rules (as of 2021) are available.
Using nlprule and symspell (for spell-checking), we can implement a simple LanguageTool API server in Rust that can then be called from a variety of contexts using LanguageTool clients.

Official LanguageTool browser extension using the Rust API server
The code and binaries can be found on https://github.com/cpg314/ltapiserv-rs.
See the README there for the configuration as a systemd service as well as the setup of the clients.
Comparison with the Java server
Running H.G. Wells’ War of the Worlds (~6k lines and 62k words) through the two servers, using hyperfine and httpie, we get:
$ docker pull erikvl87/languagetool
$ docker run --rm -p 8010:8010 erikvl87/languagetool
http://localhost:{port}/v2/check language=en-us [email protected]'
$ for port in 8875 8010; do http --form POST http://localhost:$port/v2/check \
language=en-us text=@wells.txt | jq ".matches|length"; done
1490
1045
$ hyperfine -L port 8875,8010 --runs 10 'http --ignore-stdin --meta --form POST \
http://localhost:{port}/v2/check language=en-us [email protected]'
The additional false positives in ltapiserv-rs seem to come mostly from the spell-checking.
| Command | Mean [s] | Min [s] | Max [s] | Relative |
|---|---|---|---|---|
ltapiserv-rs | 16.002 ± 0.629 | 15.566 | 17.745 | 1.00 |
java | 30.594 ± 2.372 | 29.569 | 37.296 | 1.91 ± 0.17 |
With only a paragraph (to simulate something close to the normal use of LanguageTool, say in emails):
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|---|---|---|---|---|
ltapiserv-rs | 379.7 ± 9.3 | 362.6 | 393.4 | 1.00 |
java | 706.9 ± 198.1 | 555.9 | 1226.6 | 1.86 ± 0.52 |
Command-line client
The code also contains a simple command-line client (which should be compatible with any server), ltapi-client.
$ cat text.txt | ltapi-client --server http://localhost:8875
$ ltapi-client --server http://localhost:8875 test.txt
The client uses ariadne to get a very nice graphical reporting of the errors:

Implementation
API endpoint
The LanguageTool API is documented here. It suffices to implement the HTTP POST /v2/check endpoint that processes
pub struct Request {
text: Option<String>,
data: Option<String>,
language: String,
}
and returns
pub struct Response {
pub matches: Vec<Match>,
pub language: LanguageResponse,
}
pub struct Match {
pub message: String,
pub short_message: String,
pub offset: usize,
pub length: usize,
pub replacements: Vec<Replacement>,
pub sentence: String,
pub context_for_sure_match: usize,
pub ignore_for_incomplete_sentence: bool,
pub r#type: MatchType,
pub rule: Rule,
}
The most important fields in Response are offset, length (defining the span of the suggestion), message, replacements, and Rule.
There are a couple of small tricks required to get the closed-source browser extensions to behave as expected, e.g. in displaying grammar and spelling errors with the right colours and showing tooltips.

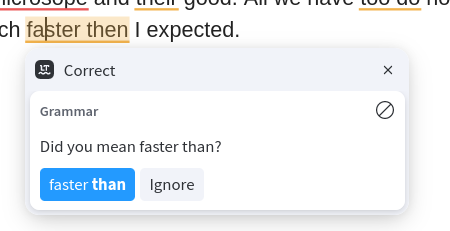
Grammar, spelling, and repetition checkers
The main functionality, returning suggestions based on an input text, can be reduced to the following method:
pub fn suggest(&self, text: &str) -> Vec<api::Match> {
let mut suggestions = Vec::new();
for sentence in self.tokenizer.pipe(text) {
debug!("Processing sentence {:#?}", sentence);
// Grammar suggestions from nlprule
suggestions
.extend(self.rules.apply(&sentence).into_iter().map(Match::from));
// Spelling and repetitions, processing the sentence token by token.
let tokens = sentence.tokens();
for (i, token) in tokens.iter().enumerate() {
// ...
}
}
suggestions
}
The Match::from method performs conversion between an nlprule::Suggestion to a Match, essentially copying over the span and the message.
The nlprule crate does not yet support spell checking, but we can add a basic version using the symspell crate and leveraging the tokenization we already have from nlprule. Similarly, the tokenization allows us to implement a word repetition rule that did not seem present in nlprule.
Future work
LanguageTool (even the original implementation with all rules) seems to be failing to identify more subtle grammatical errors:
“No one would have believed in the last years of the nineteenth century that this world were being watched keenly and closely by intelligences greater than man’s”
“With infinite complacency men went to and fro over this globe about his little affairs, serene in their assurance of their empire over matter.”
It would be interesting to understand what the state of the art is (under a fast processing constraint).
Support more languages. German is already supported in
nlprule, but adding more languages is actually non-trivial because of language-specific assumptions, see this issue and this one.Support addition and deletion of words to the dictionary. This is pretty simple and corresponds to the
/words/addand/words/deleteAPI endpoints.
Currently, the server allows passing the path to a custom dictionary at startup.Reduce the number of false positives of the spellchecker.